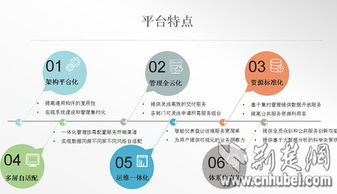
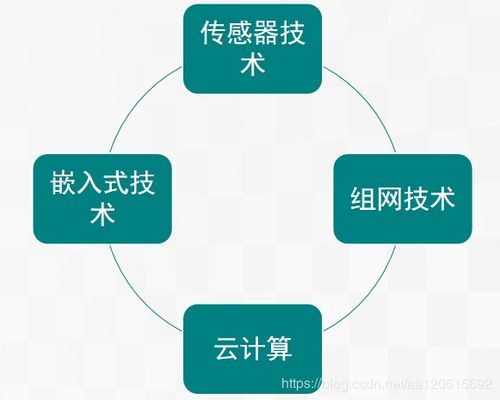
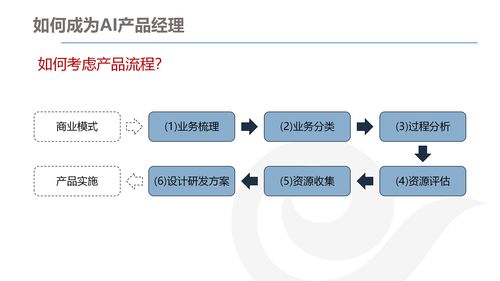
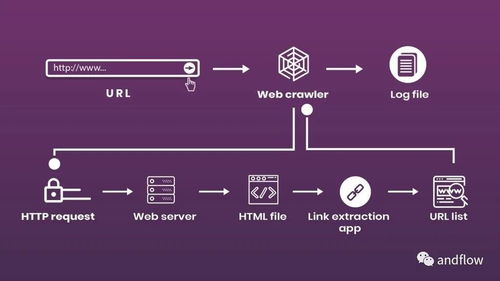
開源爬蟲是網(wǎng)絡(luò)技術(shù)開發(fā)中的重要組成部分,它通過自動化程序從互聯(lián)網(wǎng)上抓取數(shù)據(jù),廣泛應用于搜索引擎、數(shù)據(jù)分析、市場研究等領(lǐng)域。GitHub作為全球最大的開源代碼托管平臺,聚集了大量優(yōu)秀的開源爬蟲項目,如Scrapy、Beautiful Soup等。這些項目不僅提供高效的爬取框架,還允許開發(fā)者根據(jù)需求進行自定義擴展。通過學習GitHub上的開源代碼,開發(fā)者可以快速掌握爬蟲的核心技術(shù),如請求處理、數(shù)據(jù)解析和存儲。同時,CSDN等博客平臺為網(wǎng)絡(luò)技術(shù)開發(fā)者提供了豐富的教程和經(jīng)驗分享,涵蓋了從基礎(chǔ)爬蟲實現(xiàn)到反爬蟲策略的進階內(nèi)容。在實際開發(fā)中,結(jié)合開源工具和社區(qū)知識,能夠有效提升開發(fā)效率,促進網(wǎng)絡(luò)技術(shù)的創(chuàng)新與應用。
開源爬蟲項目在GitHub中的實踐與CSDN博客的網(wǎng)絡(luò)技術(shù)開發(fā)指南
更新時間:2026-04-27 09:22:01
如若轉(zhuǎn)載,請注明出處:http://www.chunella.cn/product/13.html
PRODUCT
產(chǎn)品列表
-
更新時間:2026-04-27 01:49:26
-
更新時間:2026-04-27 08:11:29
-
更新時間:2026-04-27 21:07:48
-
更新時間:2026-04-27 18:27:30